Command Prompt Windows 7 Box Drawing Characters
Windows Command-Line: Unicode and UTF-viii Output Text Buffer
In this post, we'll discuss the improvements we've been making to the Windows Console's internal text buffer, enabling it to better store and handle Unicode and UTF-8 text.
Posts in the Windows Control-Line series:
This list will be updated as more posts are published:
- Command-Line Backgrounder
- The Evolution of the Windows Command-Line
- Inside the Windows Console
- Introducing the Windows Pseudo Panel (ConPTY) API
- Unicode and UTF-8 Output Text Buffer [this post]

[Source: David Farrell'due south "Edifice a UTF-8 encoder in Perl"]
The most visible aspect of a Command-Line Terminal is that it displays the text emitted from your shell and/or Control-Line tools and apps, in a grid of mono-spaced cells – ane jail cell per character/symbol/glyph. Bully, that'due south uncomplicated. How hard can it be, correct – it'due south merely messages? Noooo! Read-on!
Representing Text
Text is text is text. Or is it?
If you're someone who speaks a linguistic communication that originated in Western Europe (e.m. English language, French, German, Spanish, etc.), chances are that your written alphabet is pretty homogenous – 10 digits, 26 separate letters – upper & lower example = 62 symbols in full. Now add around 30 symbols for punctuation and you'll need around 95 symbols in total. But if you're from East asia (e.g. Chinese, Japanese, Korean, Vietnamese, etc.) y'all'll likely read and write text with a few more symbols … more 7000 in total!
Given this complication, how do computers represent, define, shop, exchange/transmit, and return these various forms of text in an efficient, and standardized/commonly-understood mode?
In the beginning was ASCII
The dawn of modern digital computing was centralized effectually the UK and the Us, and thus English language was the predominant language and alphabet used.
Every bit nosotros saw above, the ~95 characters of the English alphabet (and necessary punctuation) can be individually represented using vii-flake values (0-127), with room left-over for boosted non-visible control codes.
In 1963, the American National Standards Institute (ANSI) published the X3.4-1963 standard for the American Standard Code for Information Interchange (ASCII) – this became the basis of what we now know as the ASCII standard.
… and Microsoft gets a bad rap for naming things 😉 The initial X3.4-1963 standard left 28 values undefined and reserved for hereafter use. Seizing the opportunity, the International Telegraph and Telephone Consultative Committee (CCITT, from French: Comité Consultatif International Téléphonique et Télégraphique) proposed a change to the ANSI layout which caused the lower-example characters to differ in bit design from the upper-case characters by just a unmarried chip. This simplified character case detection/matching and the structure of keyboards and printers.
Over fourth dimension, boosted changes were made to some of the characters and control codes, until nosotros ended upward with the now well-established ASCII table of characters which is supported past practically every computing device in use today.
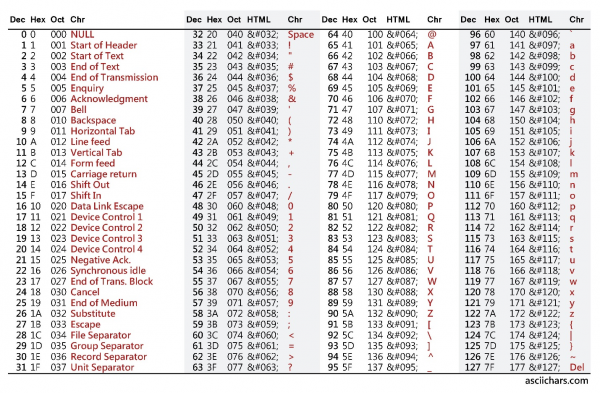
The rapid adoption of Computers in Europe presented a new challenge though: How to stand for text in languages other than English. For case, how should letters with accents, umlauts, and boosted symbols exist represented?
To accomplish this, the ASCII table was extended with the addition of an extra bit, making characters 8-bits long, adding 127 "extended characters":
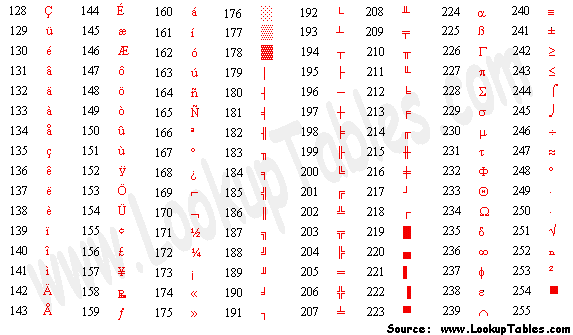
Merely that that notwithstanding didn't provide enough room to represent all the characters, glyphs and symbols required by figurer users across the globe, many of whom needed to represent and display additional characters / glyphs.
So, Code pages were introduced.
Lawmaking Pages – a fractional solution
Lawmaking pages define sets of characters for the "extended characters" from 0x80 – 0xff (and, in some cases, a few of the non-displaying characters between 0x00 and 0x19). Past selecting a unlike Code page, a Last tin can display additional glyphs for European languages and some cake-symbols (see above), CJK text, Vietnamese text, etc.
However, writing code to handle/swap Code pages, and the lack of any standardization for Code pages in general, made text processing and rendering difficult, error prone, and presented major interop & user-experience challenges.
Worse notwithstanding, 128 boosted glyphs doesn't even come up close to providing plenty characters to represent some languages: For example, high-school level Chinese uses 2200 ideograms, with several hundred more than in everyday utilise, and in excess of 7000 ideograms in full.
Clearly, code pages – additional sets of 128 chars – are not a scalable solution to this trouble.
One approach to solving this problem was to add more bits – an extra 8-bits, in fact!
The Double Byte Character Gear up (DBCS) code-page approach uses two bytes to stand for a unmarried graphic symbol. This gives an addressable space of 2^sixteen – 1 == 65,535 characters. However, despite attempts to standardize the Japanese Shift JIS encoding, and the variable-length ASCII-compatible EUC-JP encoding, DBCS code-page encodings were oftentimes riddled with issues and did non deliver a universal solution to the challenge of encoding text.
What nosotros really needed was a Universal Code for text data.
Enter, Unicode
Unicode is a set up of standards that defines how text is represented and encoded.
The pattern of Unicode started in 1987 by engineers at Xerox and Apple. The initial Unicode-88 spec was published in February 1988, and has been continually refined and updated ever since, adding new character representations, additional language support, and even emoji 😊
For a great history of Unicode, read this! Today, Unicode supports up to 1,112,064 valid "codepoints" each representing a single character / symbol / glyph / ideogram / etc. This should provide enough of addressable codepoints for the future, particularly considering that "Unicode 11 currently defines 137,439 characters covering 146 modern and historic scripts, too as multiple symbol sets and emoji" [source: Wikipedia, Oct 2018]
"1.2 million codepoints should be enough for anyone" – source: Rich Turner, October 2018 Unicode text data can be encoded in many ways, each with their strengths and weaknesses:
| Encoding | Notes | # Bytes per codepoint | Pros | Cons |
| UTF-32 | Each valid 32-bit value is a directly index to an individual Unicode codepoint | four | No decoding required | Consumes a lot of space |
| UTF-16 | Variable-length encoding, requiring either i or two 16-bit values to represent each codepoint | ii/four | Simple decoding | Consumes 2 bytes even for ASCII text. Tin apace end-up requiring four bytes |
| UCS-2 | Forerunner to UTF-16 Stock-still-length sixteen-flake encoding used internally past Windows, Java, and JavaScript | ii | Simple decoding | Consumes 2 bytes even for ASCII text. Unable to represent some codepoints |
| UTF-8 | Variable-length encoding. Requires betwixt one and four bytes to represent all Unicode codepoints | one-4 | Efficient, granular storage requirements | Moderate decoding cost |
| Others | Other encodings exist, but are not in widespread use | N/A | N/A | Due north/A |
Due largely to its flexibility and storage/manual efficiency, UTF-8 has become the predominant text encoding mechanism on the Web: As of today (October 2018), 92.4% of all Web Pages are encoded in UTF-8!
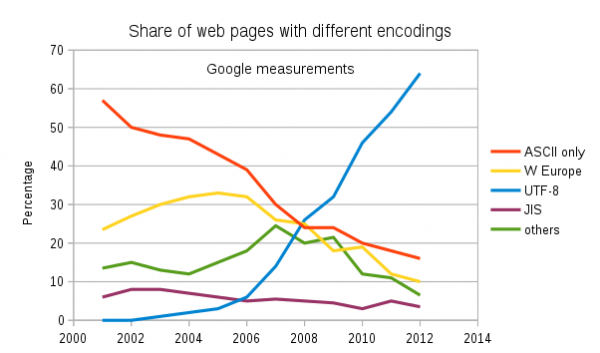
It's clear, therefore that annihilation that processes text should at least be able to support UTF-8 text.
To larn more about text encoding and Unicode, read Joel Spolsky's great writeup hither: The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
Console – congenital in a pre-Unicode dawn
Alas, the Windows Console is not (currently) able to back up UTF-8 text!
Windows Console was created way dorsum in the early days of Windows, back before Unicode itself existed! Back so, a decision was fabricated to represent each text character as a stock-still-length xvi-bit value (UCS-ii). Thus, the Panel's text buffer contains 2-byte wchar_t values per grid jail cell, 10 columns by y rows in size.
While this pattern has supported the Panel for more than than 25 years, the rapid adoption of UTF-8 has started to cause problems:
1 problem, for example, is that because UCS-2 is a stock-still-width sixteen-bit encoding, information technology is unable to represent all Unicode codepoints.
Another related but divide problem with the Windows Console is that because GDI is used to render Console's text, and GDI does non support font-fallback, Panel is unable to display glyphs for codepoints that don't be in the currently selected font!
Font-fallback is the ability to dynamically look-upwardly and load a font that is similar-to the currently selected font, but which contains a glyph that's missing from the currently selected font These combined issues are why Windows Console cannot (currently) display many complex Chinese ideograms and cannot display emoji.
Emoji? SRSLY? This might at first sound piffling but is an effect since some tools now emit emoji to, for example, indicate test results, and some programming languages' source lawmaking supports/requires Unicode, including emoji!

[Source: You can use emoji characters in Swift variable, abiding, function, and form names]
Merely I digress …
Text Attributes
In addition to storing the text itself, a Console/Terminal must shop the foreground and background color, and any other per-cell information required.
These attributes must exist stored efficiently and quickly – at that place'southward no need to store background and foreground data for each cell individually, especially since most Console apps/tools output pretty uniformly colored text, just storing and retrieving attributes must not unnecessarily hinder rendering performance.
Let'southward dig in and find out how the Console handles all this! 😊
Modernizing the Console's text buffer
Equally discussed in the previous post in this serial, the Console team have been decorated overhauling the Windows Console's internals for the final several Win10 releases, carefully modernizing, modularizing, simplifying, and improving the Console's code & features … while not noticeably sacrificing operation, and not changing current behaviors.
For each major change, we evaluate and epitome several approaches, and measure the Console's performance, memory footprint, power consumption, etc. to effigy-out the best real-earth solution. We took the aforementioned approach for the buffer improvements work which was started before 1803 shipped and continue beyond 1809.
The central outcome to solve was that the Console previously stored each cell's text data as UCS-2 fixed-length 2-byte wchar_t values.
To fully back up all Unicode characters we needed a more than flexible approach that added no noticeable processing or retentivity overhead for the general case, but was able to dynamically handle additional bytes of text data for cells that comprise multi-byte Unicode characters.
We examined several approaches, and prototyped & measured a few, which helped u.s.a. disqualify some potential approaches where turned-out to be ineffective in real-world use.
Adding Unicode Support
Ultimately, we arrived at the following architecture:
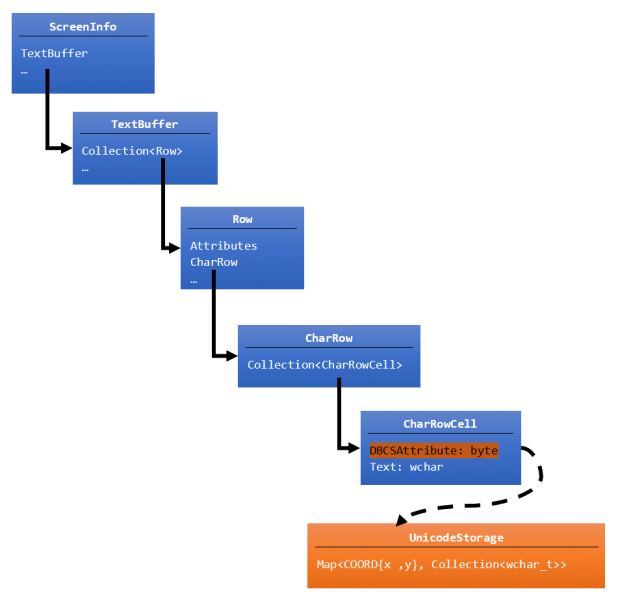
From the meridian (original buffer's blueish boxes):
- ScreenInfo – maintains information about the viewport, etc., and contains a TextBuffer
- TextBuffer – represents the Console's text surface area as a collection of rows
- Row – uniquely represents each CharRow in the console and the formatting attributes applied to each row
- CharRow – contains a collection of CharRowCells, and the logic and state to handle row wrapping & navigation
- CharRowCell – contains the actual cell'south text, and a DbcsAttribute byte containing cell-specific flags
- CharRow – contains a collection of CharRowCells, and the logic and state to handle row wrapping & navigation
- Row – uniquely represents each CharRow in the console and the formatting attributes applied to each row
- TextBuffer – represents the Console's text surface area as a collection of rows
Several central changes were made to the Console's buffer implementation (indicated in orange in the diagram above), including:
- The Console'southward
CharRowCell::DbcsAttributestores formatting information about how wide the text data is for DBCS chars. Non all bits were in utilise so an boosted flag was added to indicate if the text data for a cell exceeds one 16-bitwchar_tin length. If this flag is prepare, the Panel volition fetch the text data from theUnicodeStorage. -
UnicodeStoragewas added, which contains a map of{row:column}coordinates to a drove of 16-bitwcharvalues. This allows the buffer to store an capricious number ofwcharvalues for each private cell in the Panel that needs to store boosted Unicode text data, ensuring that the Console remains impervious to expansion to the scope and range of Unicode text data in the future. And becauseUnicodeStorageis a map, the lookup cost of the overflow text is constant and fast!
So, imagine if a cell needed to brandish a Unicode grinning face emoji: 😀 This emoji's representation in (petty-endian) bytes: 0xF0 0x9F 0x98 0x80, or in words: 0x9FF0 0x8098. Clearly, this emoji glyph won't fit into a unmarried ii-byte wchar_t. So, in the new buffer, the CharRowCell's DbcsAttribute's "overrun" flag will be set, indicating that the Panel should await-upwardly the UTF-16 encoded data for that {row:col} stored in the UnicodeStorage's map container.
A cardinal point to make about this arroyo is that we don't demand whatsoever additional storage if a character can be represented equally a single 8/16-flake value: Nosotros only need to store additional "overrun" text when needed. This ensures that for the most common case – storing ASCII and simpler Unicode glyphs, we don't increment the amount of information nosotros consume, and don't negatively touch operation.
Groovy, and then when exercise I get to try this out?
If you lot're running Windows x October 2018 Update (build 1809), you lot're already running this new buffer!
We tested the new buffer prior to including it quietly in Insider builds in the months leading-up to 1809 and made some cardinal improvements before 1809 was shipped.
Are we there yet?
Not quite!
We're too working to further improve the buffer implementation in subsequent OS updates (and via the Insider builds that precede each Os release).
The changes above but permit for the storage of a single codepoint per CharRowCell. More complex glyphs that require multiple codepoints are not still supported, but we're working on adding this capability in a hereafter Bone release.
The current changes also don't encompass what is required for our "processed input mode" that presents an editable input line for applications like CMD.exe. We are planning and actively updating the code for popup windows, command aliases, command history, and the editable input line itself to support full truthful Unicode as well.
And don't go trying to brandish emoji just still – that requires a new rendering engine that supports font-fallback – the ability to dynamically find, load, and render glyphs from fonts other than the currently selected font. And that's the bailiwick of a whole 'nother postal service for some other time 😉.
Stay tuned for more posts soon!
We look forward to hearing your thoughts – experience free to sound-off below, or ping Rich on Twitter.
![]()
Rich Turner Sr. Program Manager, Windows Panel & Command-Line
Source: https://devblogs.microsoft.com/commandline/windows-command-line-unicode-and-utf-8-output-text-buffer/